نظرة على الـ DNS كنقطة انهيار في الأنظمة

1. مقدمة
جميع الأنظمة والسيرفرات تعمل بكفاءة… لكن المستخدم عاجز عن الوصول إلى النظام!
هذا ما تبدو عليه مشاكل الـ DNS، فهو بوابة الوصول إلى الأنظمة والنقطة الأولى للتفاعل معها، ويُستخدَم داخليا للربط بين الأنظمة والخدمات المختلفة ضمن النظام الواحد.
شرحت الـ DNS وآلية عمله باختصار في مقال سابق في هذه المدونة ، أما في هذا المقال أركز على مناقشة المشاكل والأعطال والتعافي منها ومحاولة تجنبها قدر الامكان.
في تصميم النظم (System Design) لا توجد قرارات صحيحة أو خاطئة بالمطلق، المقال لا يناقش مشكلة ويعطي حلّا مباشرا، بل يطرح حلا محتملا ويعود قرار تطبيقه من عدمه إليك.
2. نظرة عامة على الـ DNS
أنصحُ بالرجوع إلى مقال [شرح الـ DNS وآلية عمله وبعض تطبيقاته ] لمزيد من التفاصيل عن الـ DNS قبل قراءة هذا المقال، وإن كنت تعرف كيف يعمل وتحتاج تذكيرا فقط، فهذه الصورة قد تكفي لذلك:
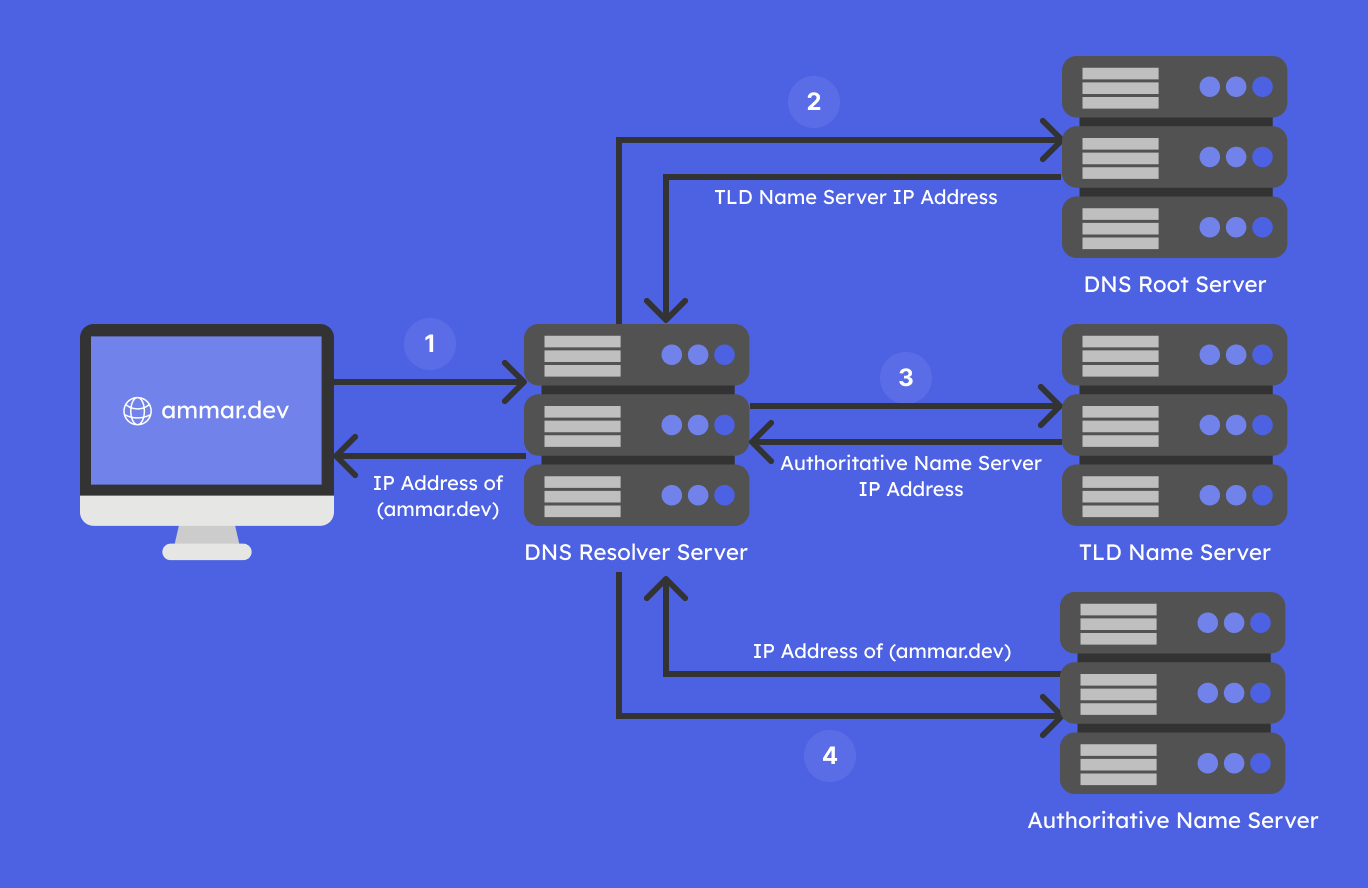
البروتوكول بسيط جدا كما تم شرحه في المقال الأول، لكنه يتكون من عدة أجزاء، الأخطاء تحصل في أي جزء منها. بعض هذه المشاكل يمكن تجنبها، والبعض الآخر يمكن التقليل من تأثيرها.
قبل مناقشة الأخطاء والمشاكل التي تحصل، لنتفق أولا على تجنب الأخطاء البسيطة كانتهاء مدة صلاحية الـ Domain، أو انتهاء صلاحية رخصة الـ TLS (لا علاقة لها بالـ DNS لكن تأثيرها مشابه).
مثل هذه الأخطاء يمكن تجنبها بسهولة عن طريق أتمتة تجديد الـ Domains والـ Certificates، إضافة إلى استخدام نظام إشعارات احتياطي في حال فشل التجديد التلقائي، مثل هذه الأخطاء لن تناقش في المقال.
3. تجَنُّبُ ما يمكن أن يمثل نقطة ضعف (Single Point of Failure)
عند مناقشة تصميم أي نظام، نقاط الضعف هي من أهم ما يجب التركيز عليه، نقاط الضعف (تعرف باسم Single Point of Failure) هي أي جزئية في النظام يؤدي سقوطها إلى توقف النظام بالكامل.
مصطلح Failure في تصميم الأنظمة لا يعني أي خطأ عابر، إنما فشل النظام في تقديم الخدمة، كعدم امكانية الوصول إليه أو عدم استجابته.
يتم حل نقاط الضعف بعدة طرق، ففي قواعد البيانات قد نلجأ للـ Replication، وللـ API Services قد نلجأ للـ Load Balancing…
مبحثنا هو ما يؤدي إلى تعطل الـ DNS وكيفية حل أعطاله، وبما أن معالجة الـ DNS هي Recursive Resolution، فالبروتوكول يمر بعدة خطوات ويتصل بعدة أجهزة فالـ Single Point of Failure قد يكون في أي جزء منها.
3.1. الـ Authoritative Name Server كنقطة ضعف
الـ Authoritative Name Server هو آخر DNS Server يتعامل معه الـ DNS Resolver ويحصل منه على الـ DNS Records، هو سيرفر عادي يقوم بالرد على استعلامات الـ DNS المطلوبة.
وجود عطل في هذا السيرفر أو توقفه يؤدي إلى عدم الرد على الاستعلامات، ما يمنع الوصول إلى موقعك!
التكرار هو الحل المناسب في هذه الحالة، بما أن الـ Authoritative Name Server يُدارُ غالبا من مزود خدمة DNS (مثل CloudFlare أو AWS Route53 وغيرها)، فمزود خدمة الـ DNS يجب أن يوفر أكثر من Authoritative Name Server الـ DNS Records فيها متزامنة، وهذه ليست مسؤوليتك بما أن الـ Server يُدار من طرفهم.
يمكنك إدارة Authoritative Name Server بنفسك بما انه مجرد سيرفر عادي يرد على استعلامات DNS خاصة اذا كانت الخدمة التي تقدمها متعلقة بالـ DNS أو كان نظامك SaaS ويحتاج إلى إدارة الـ DNS Records على جميع الـ Domains المشتركة بالنظام.. لكن هذا ليس موضوعنا حاليا ولا ينصح بذلك أصلا إلا في حالات محدودة.
تزودك خدمة الـ DNS غالبا بأكثر من Domain للـ Authoritative Name Server، بتنفيذ الأمر dig على موقعي مثلا (وهو يستخدم CloudFlare كمزود خدمة DNS):
dig NS +noall +answer ammar.dev

تجد أن هناك أكثر من NS Record من CloudFlare، فلو سقط مثلا سيرفر amanda، فسيرفر rocky سيستجيب في حال كان يعمل، قد تكون السيرفرات في كثير من مزودي الخدمة على الشكل الآتي:
ns1.example.com
ns2.example.com
ns3.example.comمثل هذا الإجراء البسيط لن يكلفك أي شيء إضافي، تأكد فقط من إضافة جميع الـ NS Domains التي يوفرها لك مزود الخدمة.
3.2. مزود خدمة الـ Name Server قد يسقط؟!
الحالة السابقة واضحة وحلها بسيط، لكن ماذا لو كانت المشكلة أكبر؟ فبدلا من أن يسقط Authoritative Name Server واحد، تسقط كلها وتتوقف.
الفشل الكامل في جميع الـ Authoritative Name Servers هو فشل على مستوى مزود خدمة الـ DNS، الحل هنا مشابه للحل السابق تقريبا.
لضمان استمرار خدمة الـ DNS حتى لو فشلت جميع سيرفرات مزود الخدمة، يمكن الأخذ بعين الاعتبار إضافة مزود خدمة آخر احتياطي، على سبيل المثال، هذه نتيجة الأمر dig على موقع LinkedIn في لحظة كتابة هذا المقال:
1dig NS +noall +answer linkedin.com
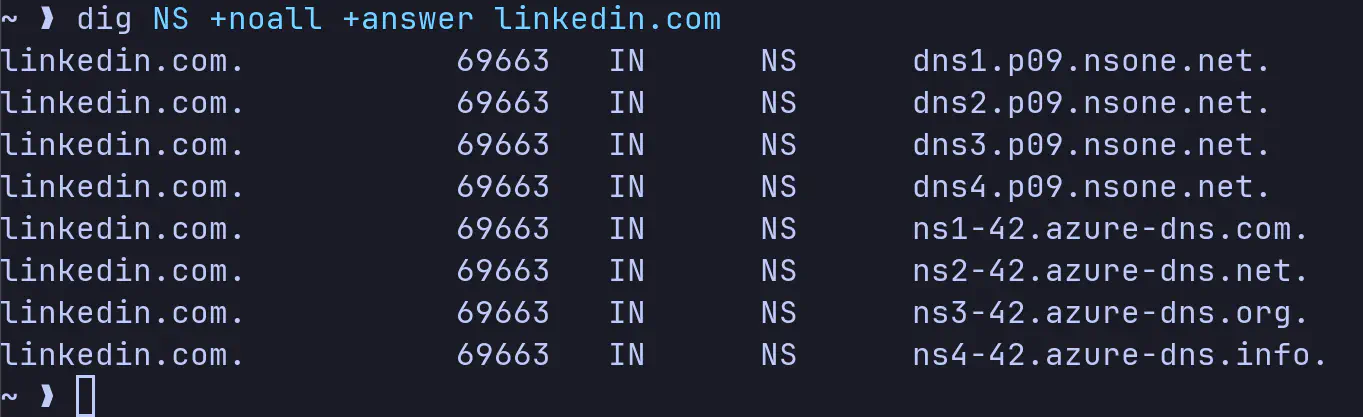
لاحظ استخدامهم لثمانية سيرفرات كل أربعة منها تنتمي لمزود خدمة مختلف، فالأربعة الأولى خدمة تقدمها IBM والأخرى من Microsoft Azure.
استخدام أكثر من مزود خدمة يعني تكلفة إضافية، هذه التكلفة تؤخذ بعين الاعتبار عند تصميم النظام ضمن المفاضلات (Trade Offs)، هل الـ Availability للنظام مهمة إلى درجة تحمل مثل هذه التكلفة؟ وما هي احتمال توقف الخدمة عند أحد المزودين أصلا؟ طرح المشكلة والحل في المقال لا يعني أن هذا هو الخيار الصحيح دائما.
استخدام أكثر من مزود خدمة يطرح مشكلة إضافية، في حالة وجود اكثر من NS ضمن مزود الخدمة الواحد، يضمن مزود الخدمة أن جميع الـ Name Servers تستجيب للاستعلامات بنفس الـ DNS Records، بينما استخدام أكثر من Name Server من أكثر من مزود خدمة يجعل مزامنة الـ DNS Records مسؤوليتك أنت.
تحديث الـ DNS Records عند اكثر من مزود خدمة يزيد من احتمالية حدوث الأخطاء البشرية، وهذا يُناقش في قسم لاحق.
3.3. الأخطاء البشرية في إدارة الـ DNS
المشاكل التي نوقشت حتى الآن متعلقة بأعطال البنية التحتية، الأخطاء البشرية تعد أيضا شائعة لأعطال الـ DNS، فإدخال قيمة خاطئة إلى الـ DNS Record قد يؤدي إلى تعطل بعض الخدمات أو توجيه المستخدمين لسيرفر خاطئ، كذلك الأمر في حال حذف بعض الـ Records.
من الأخطاء البشرية الأخرى التي قد تحصل هو ما ذكرناه في القسم السابق (3.2) عن اختلاف الـ DNS Records بين مزودي الخدمة، أخطاء المزامنة تلك تؤدي إلى اختلاف سلوك النظام بحسب المزود الذي استجاب للطلب.
توجد مشاكل أخرى لكنها أقل شيوعا، كمشكلة إضافة CNAME مع أي Record آخر على نفس الاسم، يفترض أن مزود الخدمة يمنعك من إضافة CNAME إن كان يؤدي إلى مشكلة، لكنها قد تحصل لو كنت تُدير الـ Zone Files بنفسك.
ما يزيد من كارثية مثل هذه الأخطاء هو الـ DNS Caching، ويزيد ذلك سوءا وجود TTL برقم كبير، فذلك يجعل عملية انتشار التعديل الجديد (DNS Propagation) أبطأ.
لا يمكن تجنب الأخطاء البشرية، وسنذكر بعض الأمثلة في نهاية المقال لمشاكل متعلقة بالـ DNS منها ما هو خطأ بشري، لكن أتمتة عملية إدارة الـ DNS وتنظيمها قد يقلل من هذه الأخطاء بشكل كبير.
بناء على ذلك، وَجَب مناقشة إدارة الـ TTL وتأثيرها على مشاكل الـ DNS (وذلك في رابع قسم من المقال)، إضافة إلى كيفية التقليل من الأخطاء البشرية (في القسم الخامس).
4. الـ TTL وسرعة التعافي من المشاكل
يعتمد الـ DNS بشكل كبير على الـ Caching، الـ Authoritative Name Servers تُحدث الـ Records مباشرة في قواعد بياناتها، لكن الـ Records مخزنة في الـ Cache عند المستخدمين يؤخر الحصول على القيم الجديدة، والـ TTL هو الوقت الذي تبقى فيه الـ Records مخزنة قبل إعادة تحديثها.
بناء على ذلك، إضافة أو تعديل الـ Records لا يُحدثها مباشرة عند جميع المستخدمين بسبب الـ Cache، إضافة إلى أسباب أخرى مثل عدد السيرفرات الموزعة وغيرها، ما يشكل مثالا جيدا على الأنظمة أو البيانات التي قد تكون خاطئة لكن يتم تعديلها مع الوقت (Eventually Consistent).
الوقت الذي تحدده كـ TTL بحد ذاته لا يعد سببا مباشرا في المشاكل ولا يحل المشاكل التي قد تحصل، بل هو نوع من المفاضلات (TradeOffs) التي يجب أخذها بعين الاعتبار، فعند إضافة DNS Record، نحن بين خيارين اثنين:
-
اختيار رقم كبير للـ TTL كعدة ساعات (أو قد تصل إلى يوم أو أكثر).
-
اختيار رقم صغير، من عدة ثوانٍ إلى بضع دقائق قليلة.
لاتخاذ القرار لا بد من فهم تبعيات كل خيار منهما.
وجود قيمة TTL قصيرة تعني أن التحديثات ستحصل بسرعة أكبر، الـ DNS Propagation يفترض أن يتم بشكل سريع، ولعل تأثير هذا واضح، لو اضطررت لتغيير أي Record فالتغييرات تتم بسرعة، بينما القيمة الكبيرة تجعل الـ DNS Propagation أبطأ.
تأثير ذلك على المشاكل يعتمد على طبيعة المشكلة، ويندرج ذلك تحت حالتين:
-
توجد مشكلة في الـ Record الحالي، ونريد اصلاحها.
-
الـ Record الجديد فيه مشكلة لم ننتبه لها، بينما الـ Record السابق يعطي نتيجة أفضل.
في الحالة الأولى، الـ TTL الصغير يسرع التعافي من المشكلة، بينما الـ TTL الكبير يأخذ وقتا طويلا حتى يظهر الـ Record الجديد بدلا من الفاسد عند المستخدمين.
الحالة الثانية لها تأثير مغاير، فالـ TTL الصغير يسرع من ظهور الـ Record الفاسد عند المستخدمين، على عكس الـ TTL الطويل، الذي يأخذ وقتا حتى يتم، مما يزيد من فرصة اكتشافنا للخطأ وتعديله.
4.1. متى تختار TTL قصير ومتى تختار TTL طويل
مما سبق مناقشته فإن اختيار طول الـ TTL يقع ضمن المفاضلات (Trade Offs) التي يحتاج مصمم النظام للاختيار بينها بحسب حالة الاستخدام فلا توجد قواعد ثابتة، لكن إليك بعض المقترحات التي قد تساعد بالاختيار.
استخدم TTL قصير في الحالات التالية:
-
قبل عمليات الصيانة المخطط لها: يُنصح بتقصير الـ TTL قبل الصيانة بيوم على الأقل حتى تنتشر القيمة القصيرة عند أغلب الـ Resolvers قبل بدء العمل.
-
في المراحل الأولى من تجهيز الـ Infrastructure، حيث تكثر التعديلات على الـ Records.
-
عند استخدام استراتيجيات Failover، حيث يحتاج النظام إلى تحويل الـ Traffic بسرعة في حال تعطل أحد السيرفرات.
-
للـ Records الحساسة مثل A و AAAA الخاصة بالـ API أو الخدمات الأساسية، قيمة TTL قصيرة نسبيًا تسمح بالتعامل مع المشاكل بسرعة أكبر.
يُفضَّل استخدام TTL طويل في الحالات التالية:
-
عند استقرار النظام وعدم وجود تغييرات متوقعة على الـ Records.
-
للصفحات غير الحساسة مثل Landing Pages أو الصفحات ذات المحتوى الثابت.
-
للـ Records التي تُعدّ مرة واحدة ونادراً ما تتغير، مثل MX (للبريد الإلكتروني) و TXT (للمعلومات والتحقق من الملكية).
مع كل ما سبق، يبقى الـ TTL أمرا ثانويا، تجنب الخطأ من الأساس هو الأهم، خاصة أن كثيرا من الـ Clients أو الـ Resolvers تتجاهل الـ TTL أصلا وتستخدم قيمة خاصة بها.
5. استخدام IaC لإدارة الـ DNS
الاخطاء البشرية من أهم مسببات مشاكل الـ DNS، تزداد هذه المشاكل كلما زادت الـ Records والـ Domains التي نُديرها.
إضافة إلى زيادة صعوبة الإدارة اذا استخدمنا أكثر من مزود خدمة كما ناقشنا في قسم سابق.
لا بد من الأخطاء البشرية، وتجنبها يكاد يكون مستحيلا بل هو مستحيل، لكن وجود آلية تنظم العمل تقلل كثيرا من مشاكل الـ DNS، وهذا يتمثل في استخدام الـ IaC - Infrastructure as Code (الرابط ينقلك إلى قصاصة تعرفها بشكل أكثر تفصيلا).
إدارة الـ DNS بـ IaC مع وجود مستودع Git يساعد الفريق على معرفة التغييرات وتاريخها، والتراجع عن الأخطاء بسرعة لو حصلت، إضافة إلى وجود Code Review من شخص آخر في الفريق مما يقلل الأخطاء بشكل كبير.
يفيدك ذلك أيضا لمزامنة الـ DNS Records بين أكثر من مزود خدمة، تعديل واحد في الكود مع CI/CD workflow معد بشكل جيد ويتم نفس التحديث على جميع مزودي الخدمة.
إضافة إلى تقليل أخطاءٍ مثل كتابة IP Address خاطئ، فإذا كنت تدير السيرفرات أيضا بنفس الطريقة، فيمكن الإشارة إلى اسم السيرفر بدلا من كتابة الـ IP كما في المثال الذي كتبناه في قصاصة الـ IaC:
1resource "cloudflare_dns_record" "A_my_app_ammardev" {
2 type = "A"
3 name = "my_app"
4 content = hcloud_server.apps_server.ipv4_address # الإشارة للسيرفر بالاسم تقلل من الأخطاء
5 ttl = 3600
6 proxied = false
7}الـ IaC لن يمنع الأخطاء البشرية بل سترى لاحقا في هذا المقال مثالا على خطأ بشري حصل في الكود المستخدم لإدارة الـ DNS، لكنه نقطة البداية لوضع آليات وسياسات للتعديلات والصيانات وغيرها.
6. حالات واقعية للدراسة
6.1. الهجمات على Dyn في 2016
في 2016، تعطلت سيرفرات مزود الخدمة Dyn جزئيا بسبب سلسلة من هجمات DDoS تمت باستخدام Botnet يستغل اجهزة الـ IoT لتنفيذ هجمات موزعة، استمرت الأعطال والمشاكل عدة ساعات.
وجود أكثر من NS Record تابعة لنفس مزود الخدمة كما نوقش في القسم (3.1) لم يحمِ من الهجوم، ويعود ذلك باختصار إلى سببين:
-
حجم الهجوم وأعداد الأجهزة المشاركة فيه
-
وجود بنية تحتية مشتركة بين جميع الـ Nameservers، فجزء من الفشل يحصل في البنية التحتية للشبكة قبل وصول الـ Packets لسيرفرات الـ DNS أصلا.
ما سبق ذكره من أسباب يعني أن وجود أكثر من NS Record مفيد وإن كان قد فشل في هذه الحالة بسبب حجم الهجوم ووجود بنية تحتية مشتركة بين سيرفرات الـ DNS المختلفة.
كثير من الشركات والأنظمة تأثرت بشدة بسبب هذا الهجوم، ويجدر بالذكر أن Amazon كانت تستخدم أكثر من مزود خدمة (Dyn و UltraDNS) كما ناقشنا في (3.2)، ما أدى إلى تقليل تأثير ذلك الهجوم عليها.
مزيد من التفاصيل حول الهجمة وكيفية تأثر البنية التحتية لـ Dyn واستخدام Amazon لأكثر من مزود خدمة تجده في التحليل التالي على هذا الرابط:
The DDoS Attack on Dyn’s DNS Infrastructure | ThousandEyes
6.2. عطل في Github بعد تعديلات على الـ DNS
عطل في 2014 حصل اثناء تطبيق تغييرات تهدف للحماية من هجمات DDoS، اثناء تطبيق التغييرات حدث خطأ منع من تطبيق كامل التغييرات ما أدى إلى عدة مشاكل استمرت أكثر من ساعتين.
سبب العطل كان خطأ بشريا، خيار تكرار الـ NS Records أو وجود اكثر من مزود خدمة لا يخدم تجنب هذه المشكلة، الخطأ هنا بشري.
قد يتبادر إلى ذهنك أن استخدام IaC كما نوقش في خامس قسم من المقال يحل المشكلة، لكن تقرير GitHub عن المشكلة أكد أنهم يستخدمون أداة Puppet والتعديل تم من خلالها.
المشكلة كانت في الـ Code أصلا، وهذا يؤكد على أن مجرد استخدام IaC لا يمنع الأخطاء البشرية (وإن قللها)، لكن على الاقل تتبع الخطأ يصبح اسهل، كذلك التراجع عنه. الـ IaC واستخدام أدواتها فقط لا تكفي، بل لا بد من التحقق مما تم كتابته (Validation) وبناء اجراءات وسياسات لتخفيف الأخطاء قدر الامكان وهذا ما ذكره تقرير GitHub عن الإجراءات التي سيتم اتخاذها للتعامل مع مثل هذه الأخطاء مستقبلا.
مزيد من التفاصيل في التقرير: DNS Outage Post Mortem - The GitHub Blog